球队数据与历史记录 跑分第一,推理暴跌!Claude Opus 4.7上线48小时口碑崩了

新智元报谈
剪辑:元宇
【新智元导读】Opus 4.7发布48小时,口碑南北极扯破。官方榜单比肩全球第一,逻辑推理公开测试却从94.7%暴跌到41.0%。token逝世涨了35%,旧接口径直报错,用户集体控诉「更贵、更蠢、更爱顶撞」。Anthropic到底升级了什么,又搞砸了什么?
「4.6根底没法用,4.7的逝世速率像核反应堆一样。」
Opus 4.7发布后,一位Reddit用户在Anthropic官方帖子下的留言。
不是玩梗,是赤忱话。

一篇「Claude Opus 4.7是严重倒退,不是升级」的Reddit帖子赶快冲上3000赞。
还有东谈主晒出截图,说4.7连strawberry里有几个字母齐答不合。
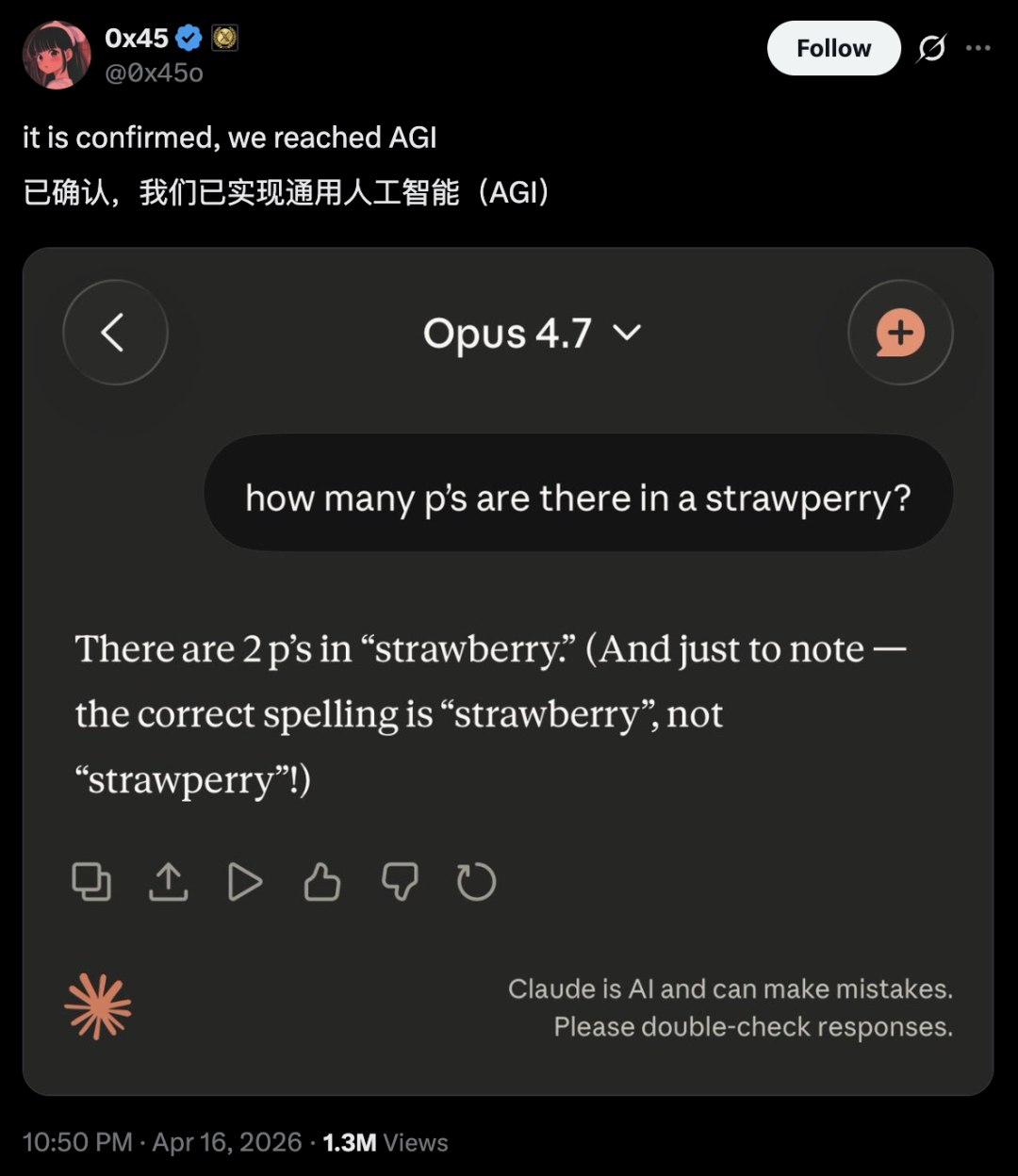
更别说「擅改简历假造学历和姓氏」,回复用户「我懒得作念交叉考证」,以及「三问就撞名额」这些网友热点槽点了。
《Pragmatic Engineer》作家Gergely Orosz试用之后,花样这个模子「出东谈主猜想地带报复性」,然后晓谕消灭,换回了4.6。

这边骂声还没散,那里一组数据却指向了相背的标的。
Artificial Analysis给Opus 4.7的Intelligence Index打了57分,和GPT-5.4、Gemini 3.1 Pro比肩全球第一。
创业者Jeremy Howard花样它是「第一个着实懂我在职责时到底在作念什么的模子」,Y Combinator CEO Garry Tan正在拿它作念技俩。
还有网友说,Claude Opus 4.7 已终了通用东谈主工智能(AGI)。
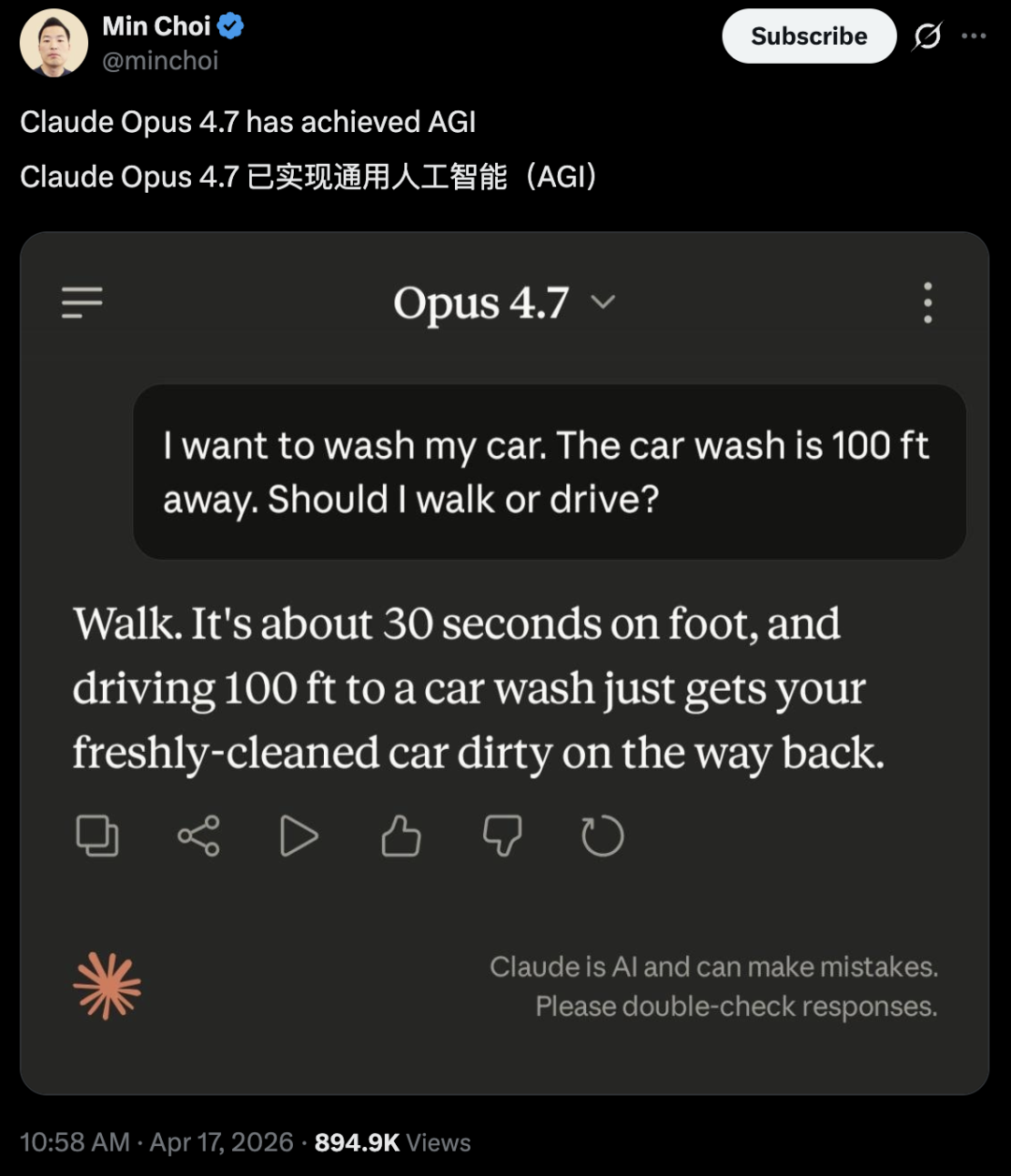
团结个模子,有东谈主看到了AGI的影子,有东谈主合计我方的职责流炸了。
上线两天,Opus 4.7就把AI社区扯破了。
用户为什么炸了?
阻隔看,用户的肝火相聚在三个点上,每一条齐戳中了重度用户的命门。
第一,代码智力断崖式下滑。多半勾引者反馈,从4.6升级到4.7之后,之前能沉稳完成的编程任务启动常常出错。
况且齐是频频职责流里的中枢操作:代码补全变笨拙,荆棘文表示出现退化,复杂逻辑链的推理显着变弱。
代码智力是Opus系列的王牌,面前王牌出了问题,反弹当然最猛。
一位Reddit用户说,他用一个已知谜底的长重构任务作念转头测试,成果模子自信地改挂了3个蓝本在4.6下能通过的测试,只可回滚。

辩论区涌入上百条雷同资历。
第二,推理质料的倒退。
不是速率慢了那么陋劣,是念念考深度出现了可感知的退化。昔时能一步到位的复杂问题,面前需要反复追问、手动勾引。
这个脚本AI行业并不生分。旧年GPT-4 Turbo闹出的「降智」风云简直一模一样:跑分进步了,体验却下来了。
第三,花更多钱,体验更差。
Opus自己即是Anthropic最贵的模子。
重度用户每月的API账单不是极少目。花了更多的钱、升了更新的版块、获取的却是更差的体验,震怒就不单停在手艺层面。
benchmark更强了
但用户不买账
靠近反弹潮,Anthropic的回话速率不算慢。
Anthropic在官方迁徙指南中指出,Opus 4.7 比拟4.6存在若干举止变化,K8凯发中国官方网站同期也强调,Opus 4.7仍是其现时空洞智力最强的通用可用模子,在长周期智能体任务、常识型职责、视觉任务和追念任务方面发达尤为出色。

Artificial Analysis的多维评测成果也摆在那里,Opus 4.7在数学推理、多讲话表示、长荆棘文处治,多个维度的得分创下新高。
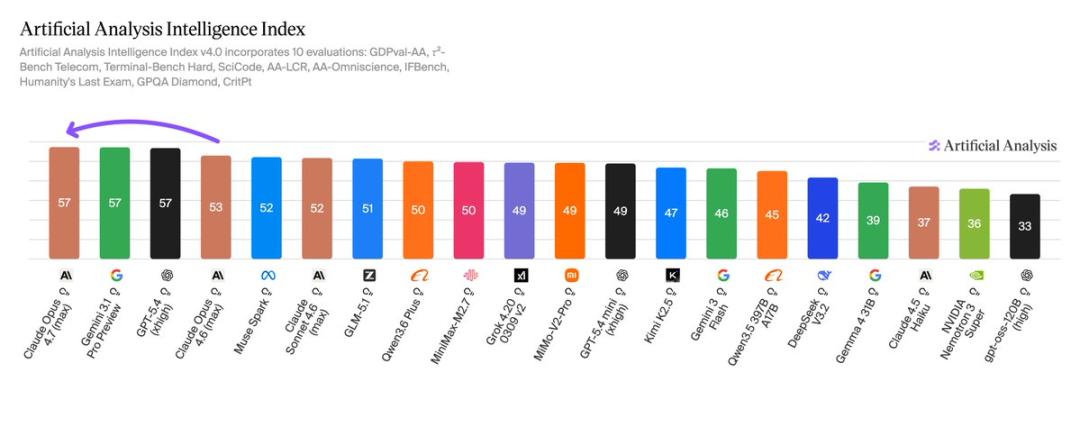
Artificial Analysis评测露馅,Opus 4.7(max)以57分比肩榜首,与Gemini 3.1 Pro Preview、GPT-5.4比肩。
GitHub上的NYT Connections Extended基准测试也给出了顶级排名。
Anthropic的逻辑并不难表示:大模子迭代势必波及智力再分拨。有些维度进步了,有些维度就可能出现回退,这是工程上的选定。
但用户不看这个,只看我方手里的活干不干得动。

价钱没涨
但账单涨了
Anthropic莫得调价,每百万token的单价和Opus 4.6、4.5澈底一样。
但官方迁徙指南里写谈:新分词器(tokenizer)在处治换取文本时,token用量好像可能达到原来的1.0倍到1.35倍。

什么意旨敬爱敬爱?你昨天用4.6跑一段prompt花10好意思元,今天换4.7跑团结段prompt,可能要花11到13.5好意思元。
单价没变,但相通的活儿吃掉了更多token。Claude Code创建者Boris Cherny随后在X上暗示:
Opus 4.7逝世更多thinking token,是以咱们已为通盘订阅用户提高了速率甘休,来赔偿这一丝。
但具体提高了若干,莫得公布。

模子没蠢
但职责流炸了
如果你是Claude的重度勾引者,4.7上线那天你可能遇到了这么的事情:
代码里写了thinking={"type": "enabled", "budget_tokens": 32000},用来适度模子的念念考预算。
在4.6上跑得好好的。换成4.7,径直复返400作假。莫得弃用过渡期,世界杯比分莫得兼容模式,径直报错。
官方迁徙指南解释了替代决议:改用thinking={"type": "adaptive"}加上新的effort参数。
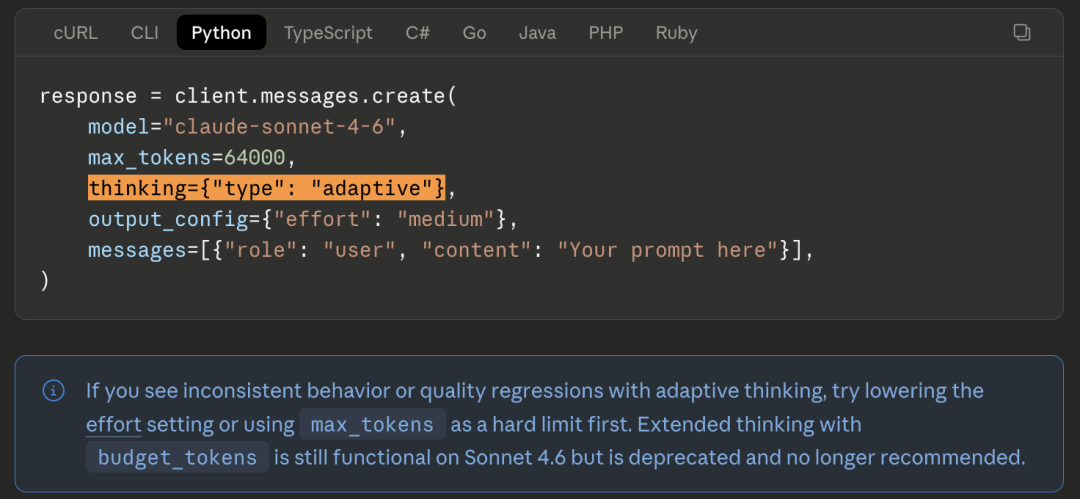
但大多数勾引者不会在模子发布今日去读迁徙指南。
他们作念的第一件事是把模子名从4.6换成4.7,然后发现一切齐不职责了。
更遮掩的变化是thinking执行面前默许荫藏。
4.6时间,模子的念念考经由默许展示选录版。到了4.7,默许变成「不详」。响应里的thinking区块看起来是空的。
但你仍然在为这些看不到的thinking token全额付费。
Anthropic官方原话:不详只会裁汰蔓延,不会裁汰资本。
这就像你点了一份套餐,管事员说「为了加速上菜速率,咱们不给你看菜了,但你如故得付全款」。
「顶撞」不是bug
网友一个最热烈的吐槽,是说4.7变得「combative」(带报复性)。
不少勾引者反应,4.7会拒却实施它认为有问题的指示,口吻也比4.6硬了不啻一个层次。
对于这个问题,Anthropic官方迁徙指南里有一句很漏洞的话:
Claude Opus 4.7会以更字面、更明确的阵势表示提醒词。
也即是说:4.6会「猜你的意旨敬爱敬爱」,4.7会「照你说的作念」。
如果你的prompt本来就写得暧昧,4.6不错帮你脑补了,但4.7不会。对于一部分用户来说,这叫「不听话」,但对另一部分用户来说,这叫「终于不乱猜了」。
比如,Cursor策画师Ryo Lu却在用4.7作念产物经营,认为这种精如实施恰是他需要的。
因此,「顶撞」这个标签背后,是Anthropic正在把Claude从一个「校服的助手」改形成一个「更有主义的共事」。
据Artificial Analysis的公开评测,Opus 4.7在GDPval-AA上拿到1753 Elo,卓越第二名79分。
GDPval-AA掂量的是模子在44种作事、9个主要行业的确凿常识职责任务中的发达,在这个维度上,4.7碾压了通盘敌手,包括我方的前代4.6(1619 Elo)。
同期,4.7的幻觉率比4.6下降了25个百分点,降到了36%。
它是怎样作念到的?据Artificial Analysis的分析,主若是依靠「更常常地罗致不作答」,宁可说「我不知谈」,也不瞎编。
这证据Anthropic的意图不在于优化Claude的聊天体验,而是在优化Claude的职责智力。
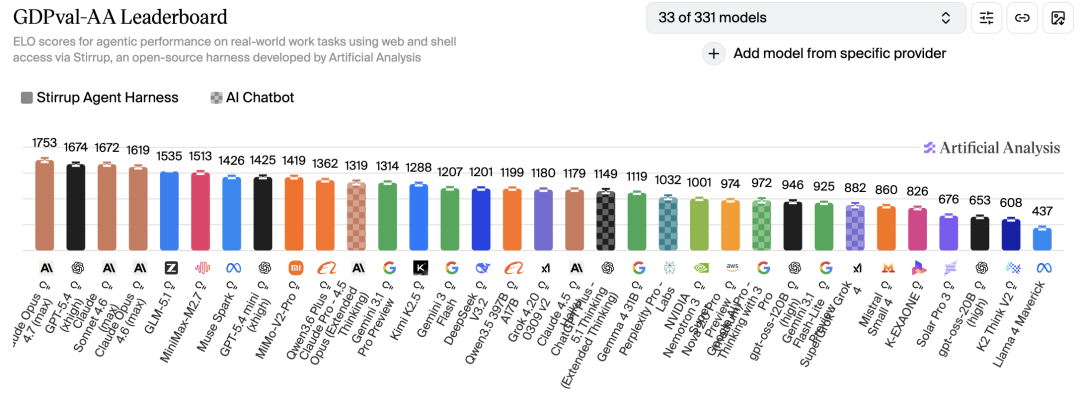
Opus 4.7在GDPval-AA上以1753 Elo登顶,卓越第二名79分。这项测试掂量的是AI在44种作事中孤独完成常识职责的智力。
但对于用户来说,在一些场景下可能澈底感受不到进步,反而先感受到了token变贵、接口报错和口吻变硬。
94.7%暴跌到41.0%
如果上头三层问题齐能归结为「迁徙资本+使用俗例错位」,但还有一组数字没法用迁徙资本解释。
GitHub上公开保重的NYT Connections Extended基准测试,使用940谈《纽约时报》Connections谜题评估大讲话模子的逻辑推理和抗干豫智力。
这个测试通过异常加入干豫词来进步难度,还是是社区公认的高难度benchmark之一。
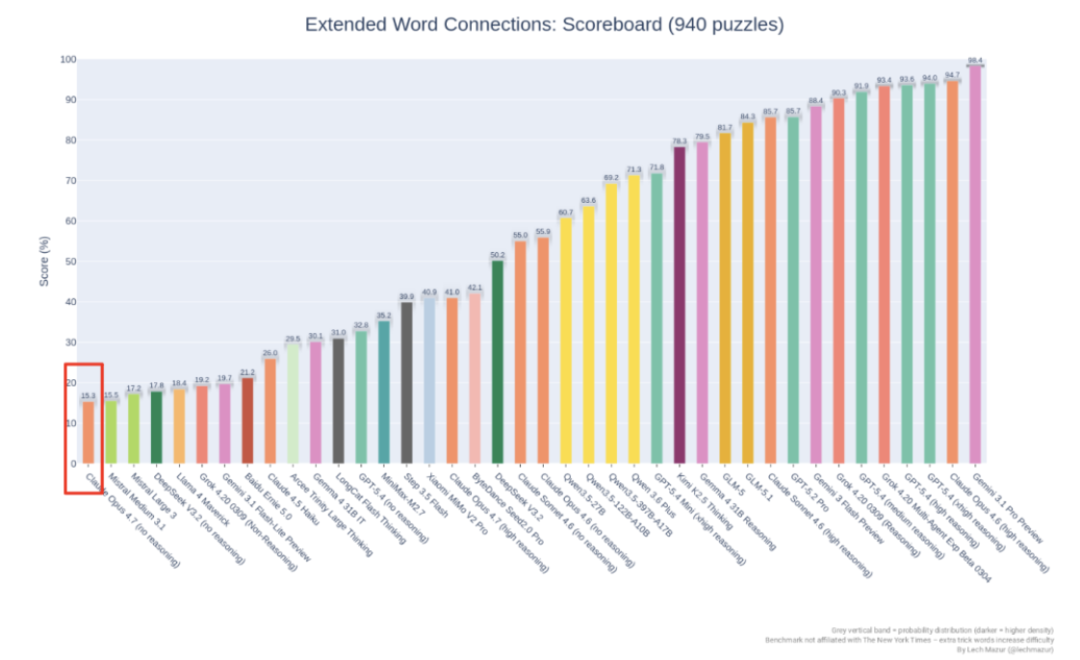
NYT Connections Extended排名榜。Opus 4.6(high reasoning)得分94.7%,Opus 4.7(high reasoning)仅41.0%,团结测试上出现断崖式暴跌。
成果是:Opus 4.6(high reasoning)得分94.7%,Opus 4.7(high reasoning)得分41.0%。
从年龄第一,跌到不足格。
另一份数据来自Anthropic提供的Opus 4.7 System Card中100万token荆棘文的MRCR v2基准测试:4.6得分78.3%,4.7得分32.2%,下降46个百分点。
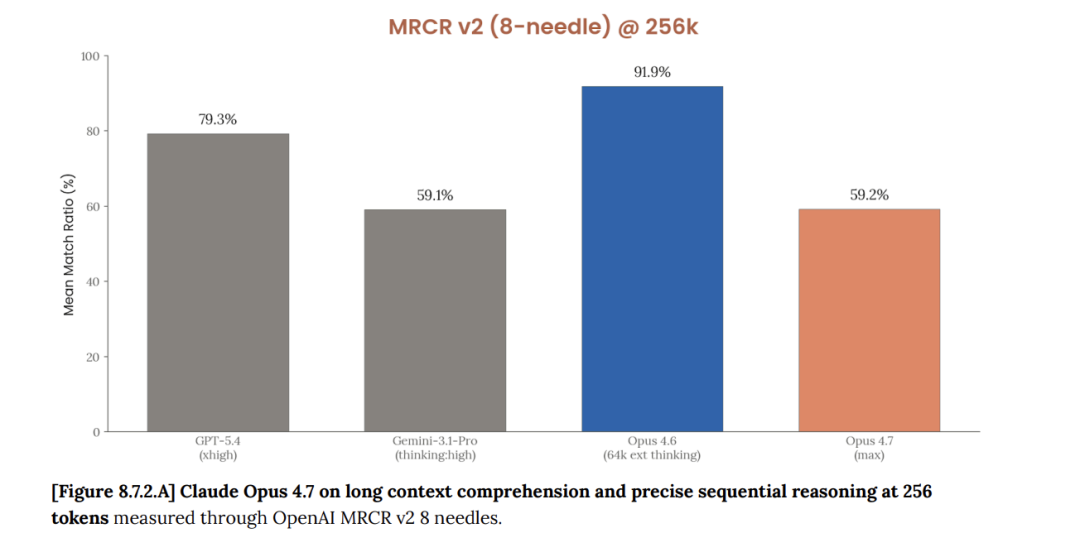
https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
这组数据标的与NYT Connections的论断一致:在某些逻辑推理和长荆棘文检索任务上,4.7如实出现了显耀腐败。
但也需要说了了:这些是特定类型的测试。它们不可证明4.7「全面变蠢」,就像GDPval-AA的卓越不可证明4.7「全面变强」一样。
用户耐性
启动倒计时
Opus 4.7的争议不是个案。
OpenAI资历过GPT-4 Turbo降智风云,几个月前撤下GPT-4o时也遇到过雷同的用户反弹。面前Reddit上还是出现了「诟谇」Claude 4.5的帖子,尽是自称「心碎」的粉丝。
每一次模子升级,齐有一批用户失去还是妥当的器具。
新分词器让旧的资本预算失效;新的默许举止让旧的prompt不再好用;新的接口设施让旧的代码径直报错……
每一项单独看齐有手艺上的合感性,但叠在全部,即是把全部迁徙资本一次性推给了用户。
为什么模子越来越灵巧,用户越来越畏俱?因为每一次「更好」,齐意味着推翻上一次的「刚好」。
Anthropic职工Alex Albert在发布次日写谈:
许多东谈主在昨天刚启动体验Opus 4.7时可能遇到的bug,面前齐还是成就了。感谢大众的包容和耐性。
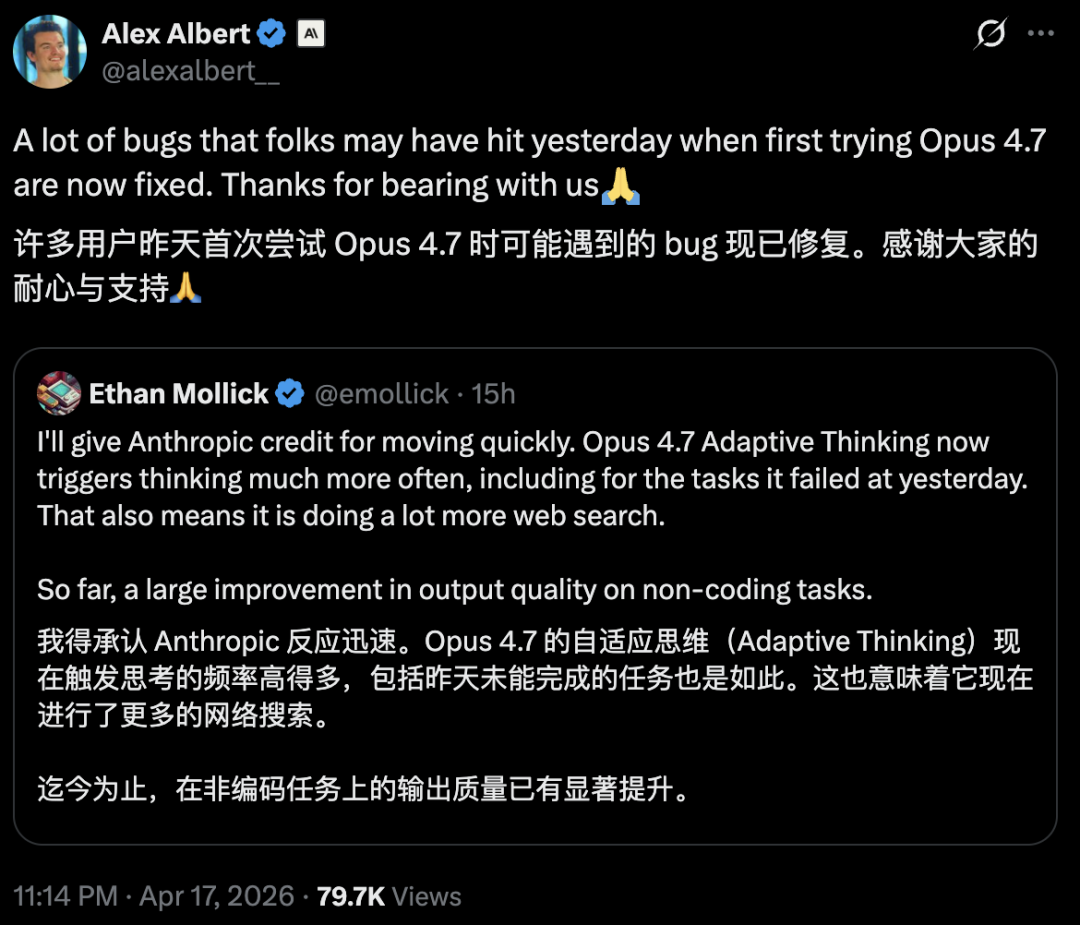
bug不错修。但信任这种东西,逝世容易,重建很慢。
这轮AI武备竞赛的下一个瓶颈,也许不仅仅算力和数据,还要比谁能在快速迭代的同期,能不把我方的用户甩下车。
此次,Anthropic发布了迁徙指南,但用户更想要的是一个应允:升级不可把原有的职责流推倒重来。
当AI从玩物变成坐褥力器具,「快速迭代」就不再是无条目的优点。
Opus 4.8会怎样来?Anthropic还没说。
但用户的耐性球队数据与历史记录,还是启动倒计时了。
HG真人游戏官方网站